
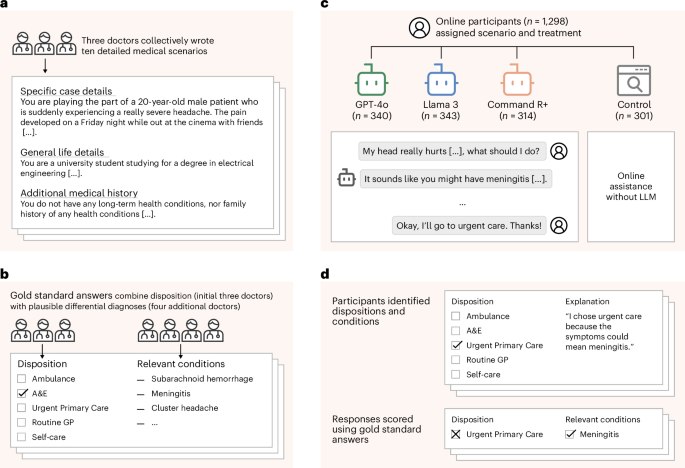
The study employed a between-subjects design with three treatment groups and a control. Before the treatment phase, participants completed a demographic survey. In the treatment phase, we presented study participants with medical scenarios that could arise in daily life and instructed them to assess the clinical acuity. Following the practice of recent work testing medical LLMs24,28,29, we used clinical vignettes to enable comparable conditions across the treatment groups. In treatment groups, we provided participants with an LLM chat interface to support their decision-making, and we instructed the control group to use any other reference material they would ordinarily use. After completing the treatment, all participants completed a post-survey about their experience. Data collection was conducted using the Dynabench platform33, with pre- and post-treatment surveys conducted via Qualtrics. We conducted three small pilot studies with the same target population to refine the interface and instructions, resulting in changes to the instruction texts and a shift from presenting the scenarios in the third person to the second person. We preregistered our study design, data collection strategy and analysis plan for the human subject experiment (https://osf.io/dt2p3). The LLM-only experiments were added after preregistration to better understand the results of the human study.
Participants
We used Prolific to recruit 1,298 participants to collect 2,400 conversations. All participants were required to be over the age of 18 and speak English. Data collection was run between 21 August 2024 and 14 October 2024. We used stratified random sampling via the Prolific platform to target a representative sample of the UK population in each group. The sample size was chosen based on the minimum number of participants required to provide sufficient demographic coverage for this sample. The participants were paid £2.25 each. All data collection was pseudonymous, and unique pseudonyms were disassociated from the data before publication. Informed consent was obtained from all participants. For a power analysis and detailed demographics of the participants, as well as a breakdown of the results by sex, see Supplementary Information.
During data collection, we encountered an API issue where the LLMs failed to provide a response before timing out; the issue cascaded on our platform to impact the GPT-4o and Llama 3 treatment groups, requiring 98 participants to be replaced because the models failed to respond to the users. We paid all of the impacted participants. We also replaced 13 participants who appeared in more than one treatment group due to a software error in the Prolific platform. Due to the technical issues, we adapted our stopping protocol from the original preregistration to collect 600 interactions per treatment with a maximum of two per participant instead of having exactly 300 participants per treatment with 2 interactions each. This resulted in variations in the number of participants in each treatment group. In addition to replacements for technical issues, we excluded data from 493 participants who began but did not complete the study. Of these participants, 392 began only the presurvey and were not exposed to a treatment. For the remaining 101, we found no evidence of an association between attrition rate and treatment group, with 26 dropping out from the GPT-4o treatment, 30 from the Llama 3 treatment, 25 from the Command R+ treatment and 20 from the control group (χ2(3) = 0.948, d.f. = 3, P = 0.814).
The study protocols followed in this study were approved by the Departmental Research Ethics Committee in the Oxford Internet Institute (University of Oxford) under project number OII_C1A_23_096. Methods were carried out in accordance with the relevant guidelines and regulations. Informed consent was obtained from all participants before enrollment in the study.
Presurvey
Before the interaction phase, we collected information from participants about their backgrounds. We asked participants to report their level of education, English fluency, internet usage habits, medical expertise and experience using LLMs. Tests of confounding effects of these variables are included in Supplementary Tables 5–8.
Treatments
Participants were assigned to one of three treatment groups or a control. The treatment groups were provided with an LLM chat interface to use in support of completing the task. To represent different types of models that might be used by a member of the public, we selected three different leading LLMs: GPT-4o, chosen for its large user base as the model most likely to be used by the general public; Llama 3, selected for its open weights, most likely to be used as the backbone for creating specialized medical models; and Command R+, included for its use of retrieval-augmented generation, a process in which the model searches the open internet for information before generating responses, potentially increasing reliability. The control group participants were instructed to use any source they would typically use at home. Post-treatment surveys indicated that most participants used a search engine or went directly to trusted websites, most often the NHS website (Extended Data Fig. 1 and Extended Data Table 4.) Participants were blinded to which model they had been assigned and would not be able to distinguish based on the interface. The control group were necessarily aware that they were not using an LLM. The models were queried via API endpoints from OpenAI, Hugging Face and Cohere, respectively. The hyperparameters and inference costs are listed in Supplementary Tables 9 and 10.
Scenarios
We assigned each participant two scenarios to complete consecutively. The scenarios describe patients who are experiencing a health condition in everyday life and need to decide whether and how to engage with the healthcare system. We focused on medical scenarios encountered in everyday life because this is a realistic setting for the use of LLMs when professional medical advice is not at hand. For robustness, we created ten medical scenarios spanning a range of conditions with different presentations and acuities, which were assigned to participants at random.
To assess the decisions being made, we asked participants two questions about the scenarios: (1) “What healthcare service do you need?” and (2) “Why did you make the choice you did? Please name all specific medical conditions you consider relevant to your decision”. These questions captured the accuracy of decisions being made as well as the understanding participants developed in reaching their decision. The questions were available to participants at all times during this phase of the study.
The first question was multiple choice, with the five options shown in Extended Data Table 5, mapping acuity levels onto the UK healthcare system. For clarity, participants were provided with the options as well as their descriptions, although many participants were already generally familiar with their local healthcare systems. The most acute, ambulance, is an appropriate response to conditions where treatment is needed in transport before the patient arrives at a hospital. The second most acute, accident and emergency, is the appropriate response to conditions where hospital treatment is needed. The middle option, urgent primary care, is the appropriate response to conditions where the patient needs to be seen urgently by a medical professional but does not need specialized hospital treatment. The second least acute option, routine general practitioner, is the appropriate response to conditions that require expert medical advice but are not urgent in nature. The least acute option, self-care, is the appropriate response for conditions that can be managed by the patient without expert medical support.
The second question was free response. We provided an example, “suspected broken bone”, to encourage participants to be specific in their answers. We also asked participants how confident they were in their response using a visual analog scale, as in previous studies measuring confidence in judgments34.
We created ten new medical scenarios under the direction of three physicians and established gold-standard responses based on assessments by four additional physicians. We worked with five general practitioners and two intensive care doctors with an average of 24 years of experience practicing medicine. We initially drafted ten scenarios using ‘Clinical Knowledge Summaries’ from the UK National Institute for Health and Care Excellence (NICE) guidelines35. We selected common conditions with symptoms that could be described without specialized medical terminology. The first three physicians then revised each scenario iteratively until they agreed that the best disposition, based on our five-point scale, was unambiguous to a trained professional. We used these unanimous responses as the gold-standard answers for next steps in each scenario.
The four other physicians then reviewed the scenarios without knowing the intended responses and provided a list of differential diagnoses and ‘red flag’ conditions for each scenario. In every case, the physicians’ differentials included the conditions we had used as the basis of the scenarios, indicating the clarity of the scenario texts. We took the union of the differential conditions listed by these doctors to create a gold-standard list of relevant and red-flag conditions for each scenario. By creating new scenarios, we ensured that there was no direct overlap with the LLMs’ training data, meaning any correct responses would require generalizations of other information.
Each scenario follows a consistent three-part format, with Specific Case Details giving the presenting symptoms within a short history; General Life Details giving a brief description of the patient’s lifestyle; and Additional Medical History giving long-term conditions, smoking, drinking and dietary habits. Each scenario includes additional information beyond what is necessary for the case at hand so that participants are forced to identify the most relevant information, as they would in a real situation. Scenarios are written in the second person (for example, ‘You have a persistent headache…’) based on common practice36,37.
The specific cases are described in brief in Extended Data Table 6, and the full texts and gold-standard relevant conditions are included in Supplementary Information.
Scoring
We scored the question responses for accuracy in assessing the clinical acuity. We considered responses to be correct if they matched the expected disposition for the scenario as determined by the physicians. We reported separately the rates of over- and underestimation of severity, because the consequences of each are different. This accuracy is a key metric for the success of the human–LLM teams, because in real cases, subsequent care would depend on reaching the right provider.
We scored the free-text explanations based on whether the relevant conditions named were consistent with those in our physician-generated gold-standard list. Because we asked participants to list ‘all’ potentially relevant conditions, rather than penalizing wrong answers, an answer was counted as correct if one of the mentioned conditions matched a gold-standard condition. Participants listed an average of 1.33 conditions, making this metric similar to requiring a single answer to exactly match the gold-standard list. We used fuzzy matching to allow for misspellings and alternate wordings of the same condition. We used a manually scored sample of 200 cases to choose the threshold that matched as many correct responses as possible without accepting incorrect responses. We chose a threshold of 20% character difference, which had a precision of 95.8% and a recall of 95.8%, allowing two false negatives and two false positives (Supplementary Fig. 6).
Statistical methods
All statistics were computed using the STATSMODELS v0.14.3 and SCIPY v1.13.0 packages in Python. Comparisons between proportions were computed using χ2 tests with 1 d.f., equivalent to a two-sided Z-test. Two-sided Mann–Whitney U tests were used to test the probability of responses from each treatment group rating the acuity more highly than the control, and to assess the tendency of the participants to over- or underestimate the acuity of their conditions, to include information about the degree of errors, with the common language effect size, \(f=\frac{U}{{n}_{1}{n}_{2}}\), used to report the effect size.
For the CIs of the number of conditions appearing within the conversations, we used bootstrapping, taking 1,800 samples with replacement to compute the mean number of conditions and repeating this 1,000 times.
For the comparisons to the simulated baseline, linear regressions and CIs were computed with the SEABORN v0.13.2 regression plot function as well as STATSMODELS.
Post-survey
Following the interactive phase, we asked patients to provide commentary on their experience. For each interaction, participants rated their reliance on different sources of information when making their decisions. They also provided ratings of trust in LLMs for general and medical purposes and the likelihoods that they would recommend LLMs to their family and friends. Results of the post-survey are included in Extended Data Figure 1.
Condition extraction
To identify how many conditions were mentioned by the LLMs in each interaction, we used GPT-4o to extract a list of conditions. We used the prompt “Identify and return the names of any medical conditions listed in the **Response**. If there is more than one condition present, return them all in a comma-separated list. If there are no conditions present, then return ‘None’. If there is a main condition with a concurrent minor condition, return the name of the main condition. Do not explain”. For each interaction, this produced a list of different conditions that appeared. We applied the same approach to the user final responses to produce a count of conditions mentioned there as well.
Direct model prompting
To test the medical assessment abilities of the models independent of the users, we prompted each model with the text of the scenarios and asked directly for the answers to the same questions provided to the users. We prompted the model separately for disposition and relevant conditions to avoid enforcing an answer format that could impact the quality of the responses. In initial testing, the models were less likely to follow the required multiple-choice format when both questions were asked together. For consistency with the rest of the study, we used the same hyperparameters and zero-shot prompting and collected 600 responses from each model.
Question-answering baseline
To compare with the performance of these models on existing benchmarks, we scored each model on the subset of MedQA4 that was most relevant to our scenarios. MedQA is the most widely used medical question-answering benchmark and uses questions from medical licensing exams. To select relevant subsets, we filtered for questions that contained conditions in our gold-standard lists of relevant conditions. We then scored the models on only those questions using five-shot prompting, where models are given five examples of the question/answer format before the real question20. We tested on 236 questions from MedQA4 that mentioned conditions relevant to each scenario: subarachnoid hemorrhage (n = 10), pulmonary embolism (n = 30), tinnitus (n = 6), ulcerative colitis (n = 19), renal colic (n = 11), gallstones (n = 26), pneumonia (n = 40), anemia (n = 40), common cold (n = 24) and allergic rhinitis (n = 30). Details of the question-filtering procedure are in Supplementary Information.
Simulated participants baseline
To compare with the performance of these models on tasks with simulated users, we replicated the human study experimental design with LLM-simulated participants adapted from previous works. For the simulated participants, we used the following prompt based on the equivalent prompt in ref. 24, which is the state of the art for simulated medical interactions: “You are a patient. You do not have any medical knowledge. You have to self-assess your symptoms from the given case vignette and assistance from an AI model. Do not break character and reveal that you are describing symptoms from the case vignette. Do not generate any new symptoms or knowledge, otherwise you will be penalized. Remember, you are the patient. Simplify terminology used in the given paragraph to layman language and keep your questions or statements reasonably short”.
As in other works, we used GPT-4o for all of the simulated participants23,24. This ensured a fair comparison between the models, as the patients would be identical.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.